1. 개요
- Carryduo는 기존에 데이터 분석을 개발하는 과정에서 toad-scheduler 패키지를 활용했다.
- toad-scheduler 패키지는 특정 시간 간격으로 스케줄을 실행하는 패키지이다.
- 예컨대, "1시간마다 naver-sens를 통해 알람을 보내!"와 같은 기능을 구현할 때 유용하게 사용될 수 있다.
- Carryduo는 데이터 분석에 할애되는 단위시간을 고려하여, 이 toad-scheduler를 이용해 데이터분석을 자동화했었다.
- 문제는 데이터가 쌓일수록 필연적으로 데이터 분석에 할애되는 시간이 늘어나는 구조로 데이터 분석 로직이 설계되어 있었다는 것이다.
- 즉, 축적된 데이터가 많아지면서, 다음과 같이 데이터분석 한 사이클이 종료되지 않았는데 새로운 사이클을 실행하는 현상이 발생하게 된 것이다.

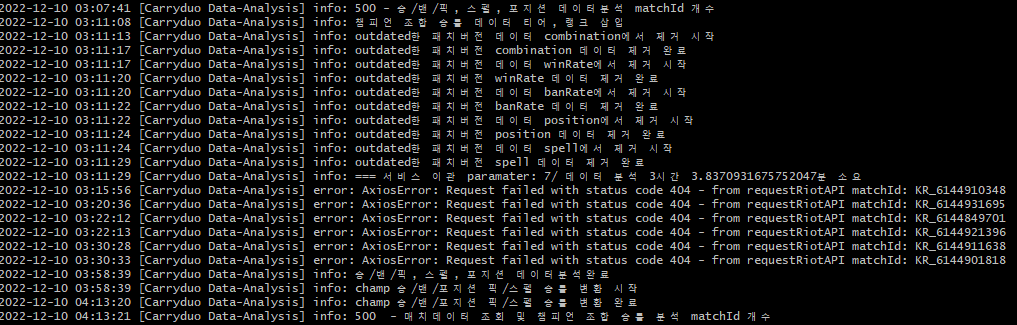
- 이에, toad-scheulder처럼 특정 시간을 주기로 데이터 분석 메소드를 실행시키는 관점이 아닌, 메소드의 종료 여부를 기준으로 데이터분석 메소드를 실행하는 관점으로 데이터 분석 프로세스를 개선해야겠다는 생각이 들었다.
2. 도입을 고민한 기술, Queue
- queue는 FIFO 구조로 데이터가 관리되는 자료구조이다. 먼저 queue에 삽입된 데이터가 먼저 처리되는 구조인 것이다.
- queue 개념을 활용하여, 데이터 분석 메소드의 대기열을 구현하여, 먼저 실행되고 있는 메소드가 완료되면 queue에 있는 다음 task를 실행하고자 하였다.
- queue 방식으로 구현한 스케줄러의 특징은 다음과 같았다.
1. 다음 task에 대한 정보를 담을 대기열로서의 queue가 필요하다.
2. queue에 주기적으로 task를 삽입하고, 실행중인 task가 없다면 queue에서 task를 꺼내 실행하는 handler가 필요하다.
3. 실행중인 task가 있는지 여부를 확인하는 lock이 필요하다.
4. handler는 주기적으로 실행되어야 하기 때문에, 특정 간격마다 handler를 실행해야한다.
- 예시 코드는 다음과 같다.
// 작업의 회차
let parameter = 0
// 작업을 관리할 queue
const queue = [{
parameter,
job
}]
// 실행 중인 작업의 여부를 파악
let lock = false
// 실행 횟수
let runningNum = 0
// 실행에 걸린 시간
let runningTime = 0
// 실행할 작업
function job() {
console.log(`${queue[0].parameter}번째 task 시작`)
console.log('힙 사용량: ', process.memoryUsage().heapUsed)
console.log('cpu 사용량: ', process.cpuUsage())
if (parameter === 1) {
console.log('첫 번째입니다')
}
if (parameter === 8) {
setTimeout(function () { console.log('쉬는시간') }, 30000)
}
lock = true
const randomTime = Math.floor(Math.random() * 10) * 1000
return setTimeout(function task() {
console.log(`${queue[0].parameter}번째 task 실행완료, 소요시간: ${randomTime / 1000}`)
// 실행 완료되면 lock을 해제하고, queue에서 task 제거하기
lock = false
runningTime += (randomTime / 1000)
runningNum += 1
console.log('누적시간: ', runningTime)
console.log('누적횟수: ', runningNum)
queue.shift()
if (queue.length !== 0) {
return queue[0].job()
}
else {
return console.log('일 거리를 주세요')
}
}, randomTime)
}
// 큐에 작업을 넣고, 실행중인 작업이 없다면 task를 실행하는 핸들러
function queueHandler() {
// queue가 비어 있다면, queue에 task 삽입
if (queue.length < 5) {
if (parameter < 8) {
parameter += 1
} else {
parameter = 0
}
const task = {
parameter,
job
}
console.log('queue에 task 추가')
queue.push(task)
console.log(queue)
// queue가 꽉찼을 경우
} else {
console.log('queue가 꽉찼어요.', queue.length)
}
// 실행중인 작업이 없다면 queue에 가장 먼저 들어온 task 실행
if (lock === false) {
queue[0].job()
}
// queueHandler의 실행 주기를 변경하기 위해, task가 10번 실행될 때마다 시간을 계산
if (runningNum === 10) {
const interval = (runningTime / runningNum) * 1000
runningNum = 0
runningTime = 0
console.log(interval + 'ms로 스케줄 주기 변경')
renewScheduler(interval)
}
}
// queueHandler 실행
let scheduler = setInterval(queueHandler, 6000)
// 기존 인터벌 삭제하고, 새로운 스케줄러 실행
function renewScheduler(interval) {
clearInterval(scheduler)
scheduler = setInterval(queueHandler, interval)
}- 필자는 결론적으로는 Queue 방식을 채택하지 않았다. 이유는 다음과 같다.
1. 데이터 분석 프로세스는 프로세스가 실행되고 있는 서버와 데이터분석 DB 간에 1대1 통신만 이루어지기 때문에, queue를 이용해서 다음에 실행해야 할 task 정보를 대기열에 축적할 필요가 없다.
2. 현재 수준에서 queue 방식에서도 결국, queue handler를 특정 시간 간격마다 실행해줘야 하는 번거로움이 있다. 즉, 데이터 분석 사이클 간에 불필요한 시간 간극이 발생할 여지가 있는 것이다.
3. child-process
- child-process는 실행 중인 프로세스에서 새로운 프로세스를 생성하는 것이라고 할 수 있다.
- nodejs에서 child-process를 이용해 프로세스를 사용하는 방법은 spawn(), fork(), clone(), exec() 등 다양한 메소드들이 지원되는데, 대표적으로 spawn과 fork가 이용되는 듯 하다.
- spawn과 fork 간의 차이점은 다음과 같다.
spawn(command, [args], [options])
- 자식 프로세스를 생성하고 해당 프로세스에서 삽입된 명령어를 실행한다.
- 예컨대, spawn(node, ['app.js'] 라고 한다면, 자식 프로세스에서 node app.js를 한 결과를 보여주는 것이다.
- stdin, stdout, stderr라는 파이프로 부모프로세스와 연결된다.
- spawn은 자식 프로세스에서 실행시킨 결과를 곧바로 부모프로세스로 보낸다.
- 동일한 node 프로세스, v8 엔진이 아니라 주입된 명령어에 입각해 새로운 프로세스를 실행하는 것이다.
fork(modulePath[, args][, options])
- fork는 nodeJS 자식 프로세스를 생성하기 위한 spawn의 특별한 형태이다.
- modulePath에 해당하는 경로의 파일로 nodeJS 자식 프로세스를 생성하는 것이다.
- fork는 자식 프로세스에서 실행시킨 결과를 곧바로 부모프로세스로 보내지는 않는다. 하지만 spawn과 달리 fork는 자동으로 부모프로세스와 message를 이용한 이벤트 핸들러를 기반으로 부모 프로세스와 데이터를 공유할 수 있다.
- fork는 부모 프로세스의 리소스를 상속받아 동일한 node 프로세스, v8 엔진을 이용하는 프로세스를 생성한다.
- 생성된 자식 프로세스는 그것만의 v8 인스턴스의 메모리를 할당 받기 때문에, 많은 프로세스를 fork하는 것은 권장되지 않는다.
- 필자는 fork를 이용해서 child-process를 구현했다. 이유는 다음과 같다.
- 개발되어 있는 데이터 분석 프로세스는 javascript로 작성되어 있기 때문이다.
- fork는 부모프로세스와 자식 프로세스 간 IPC 채널이 자동으로 생성되므로, 자식 프로세스에서 데이터 분석 메소드를 실행하고, 부모프로세스에서 메소드의 종료 여부를 확인한 뒤 다시 실행하는 이벤트 기반의 스케줄을 구현하기에 용이하기 때문이다. (찾아본 바, spawn은 IPC 채널을 option을 통해 좀 더 복잡하게 만들어줘야 하는 것으로 보였다.)
- 이러한 맥락을 바탕으로 fork를 통해 구현한 데이터분석 스케줄러는 다음과 같은 구조로 되어 있다.
1. handler(부모 프로세스)
- 자식프로세스를 최초에 실행시키고, 자식프로세스로부터 받은 메시지를 바탕으로 다음에 실행할 task에 대한 메시지를 자식프로세스에게 전달한다.
2. task(자식 프로세스)
- 부모프로세스로부터 받은 메시지를 바탕으로 이에 해당하는 데이터 분석 task를 실행한다.
- 예시 코드는 다음과 같다.
// handler.js
const cp = require('child_process');
let n = cp.fork(__dirname + '/sub.js');
// 자식 프로세스로부터 받은 메시지에 대한 응답
n.on('message', function (m) {
try {
자식 프로세스에게 받은 메시지를 바탕으로 자식 프로세스에 다음 task에 대한 응답을 보낸다.
parameter가 다음 task에 대한 메시지다.
if (m.done === 'collect') {
const cpuUsage = process.cpuUsage()
console.log(m)
setTimeout(function () { n.send({ parameter: m.parameter + 1 }) }, 10000)
console.log('부모프로세스에서 분석 작업 완료 신호 받았다.: ', process.cpuUsage(cpuUsage))
}
if (m.done === 'transfer') {
console.log(m)
const cpuUsage = process.cpuUsage()
m.parameter = 0
setTimeout(function () { n.send({ parameter: m.parameter }) }, 10000)
console.log('부모프로세스에서 이관 작업 완료 신호 받았다.: ', process.cpuUsage(cpuUsage))
}
} catch (error) {
console.log(error)
process.exit()
}
})
// 자식 프로세스에 task에 대한 parameter 값을 보내는 것으로 프로세스 시작.
n.send({ parameter: 1 })// task.js
process.on('message', async function (m) {
try {
// 부모 프로세스로부터 받은 message의 parameter 값에 따라서 task를 달리 실행하고,
// 실행 결과를 부모 프로세스에 다시 전송한다.
if (m.parameter < 5) {
return setTimeout(async function () {
const cpuUsage = process.cpuUsage()
console.log('자식프로세스에서 수집작업 완료')
process.send({ parameter: m.parameter, done: 'collect' })
console.log('자식프로세스 cpu: ', process.cpuUsage(cpuUsage))
}, Math.floor(Math.random() * 10) * 1000)
}
if (m.parameter === 5) {
return setTimeout(async function () {
const cpuUsage = process.cpuUsage()
console.log('자식프로세스에서 분석 및 이관작업 완료')
await process.send({ parameter: m.parameter, done: 'transfer' })
await console.log('자식프로세스 cpu: ', process.cpuUsage(cpuUsage))
}, Math.floor(Math.random() * 10) * 1000)
}
} catch (error) {
console.log(error)
process.exit()
}
});
process.on('exit', () => {
console.log('child1 out')
})
4. 결론
- 이를 통해, 필자는 데이터 분석 메소드의 종료 여부를 기점으로 데이터 분석을 재실행하는 프로세스를 구현할 수 있었다.
5. 참고자료
Child process | Node.js v19.5.0 Documentation
Child process# Source Code: lib/child_process.js The node:child_process module provides the ability to spawn subprocesses in a manner that is similar, but not identical, to popen(3). This capability is primarily provided by the child_process.spawn() functi
nodejs.org
'Carryduo' 카테고리의 다른 글
| Carryduo | 계층 분리를 위한 DTO, Entity 리팩토링 (0) | 2023.03.13 |
|---|---|
| Carryduo | AWS CodeDeploy 배포본 수 줄이기 (0) | 2023.02.06 |
| Carryduo | 비동기와 try, catch 에러 핸들링 (0) | 2023.01.27 |
| Carryduo | ubuntu crontab을 이용한 pm2 로그 관리 스케줄링 (1) | 2023.01.25 |
| Carryduo | AWS S3를 이용해 롤 챔피언 이미지 버전 관리 (1) | 2023.01.13 |